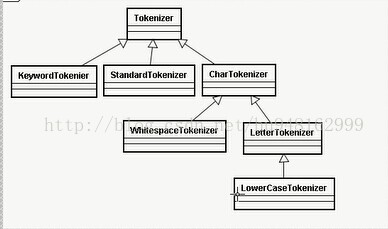
分词器的核心类:
Analyzer: 分词器
TokenStream: 分词器做好处理之后得到的一个流。这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元。
以下是把文件流转换成分词流(TokenStream)的过程
测试:
Analyzer: 分词器
TokenStream: 分词器做好处理之后得到的一个流。这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元。
以下是把文件流转换成分词流(TokenStream)的过程
首先,通过Tokenizer来进行分词,不同分词器有着不同的Tokenzier,Tokenzier分完词后,通过TokenFilter对已经分好词的数据进行过滤,比如停止词。过滤完之后,把所有的数据组合成一个TokenStream;以下这图就是把一个reader转换成TokenStream:

这个TokenStream中存有一些属性,这些属性会来标识这个分词流的元素。
在这个流里 有很多属性。下面截了lucene4.10.1源码中的图:

其中有3个重要的属性,CharTermAttribute(保存相印的词汇),OffsetAttribute(保存各个词汇的偏移量),PositionIncrementAttribute(保存各个词与词之间的位置增量,如果为0,可以做同义词搜索)。是由这3个属性来控制这些分词信息
Tokenzier 主要负责接收Reader,将Reader进行分词操作,有如下一些实现类
TokenFilter 将分词的出来的单元,进行各种各样的过滤。
代码如下:
<span style="font-size:14px;">package hhc;
import java.io.IOException;
import java.io.StringReader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.apache.lucene.analysis.tokenattributes.PositionIncrementAttribute;
import org.apache.lucene.analysis.tokenattributes.TypeAttribute;
public class AnalyzerUtil {
/**
* 输出字符分词信息
*
* @param str
* @param a
*/
public static void displayAllToken(String str, Analyzer a) {
try {
// 所有的分词器都必须含有分词流
TokenStream stream = a.tokenStream("content", new StringReader(str));// 放回一个TokenStream;
/**
* 创建一个属性,这个属性会添加到流里,随着这个TokenStream流增加
* 这个属性中保存中所有的分词信息
*/
CharTermAttribute cta=stream.addAttribute(CharTermAttribute.class);
//位置增量的属性,存储词之间的距离
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
//储存每个词直接的偏移量
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//使用的每个分词器直接的类型信息
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);
for (; stream.incrementToken();) {
System.out.print(pia.getPositionIncrement()+":");
System.out.print(cta+":["+oa.startOffset()+"-"+oa.endOffset()+"]-->"+ta.type()+"\n");
}
System.out.println();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
</span>测试:
<span style="font-size:14px;"> @Test
public void hhcTest(){
Analyzer a1 =new StandardAnalyzer(Version.LUCENE_35);
Analyzer a2 =new StopAnalyzer(Version.LUCENE_35);
Analyzer a3 =new SimpleAnalyzer(Version.LUCENE_35);
Analyzer a4 =new WhitespaceAnalyzer(Version.LUCENE_35);
String txt ="how are you think you";
AnalyzerUtil.displayAllToken(txt, a1);
AnalyzerUtil.displayAllToken(txt, a2);
AnalyzerUtil.displayAllToken(txt, a3);
AnalyzerUtil.displayAllToken(txt, a4);
}</span>